Architecture
Zephyr is a distributed edge deployment platform that integrates directly with JavaScript build tools including but not limited to rspack, webpack, rollup, rolldown, vite, parcel and repack - to provide instant deployment and global distribution of web applications.
This document details the technical architecture, design decisions, and implementation strategies that enable sub-second deployments and millisecond-latency serving.
The platform achieves its performance characteristics through a combination of compile-time integration, intelligent asset processing, and a globally distributed edge network.
By intercepting the build process at the bundler level, Zephyr can analyze, optimize, and deploy applications without modifying the build output or requiring changes to existing workflows.
Core Architecture Principles
Zephyr's architecture is built on several key principles that drive its design:
Non-invasive Integration: The platform integrates through plugins that preserves existing bundler configurations while adding deployment capabilities.
Edge-first Design: All serving infrastructure operates at the edge, utilizing a global network of workers to minimize latency and maximize availability.
Content-addressed Storage: Assets are stored and retrieved using content-based addressing, enabling perfect caching, deduplication, and atomic deployments.
System Architecture Overview
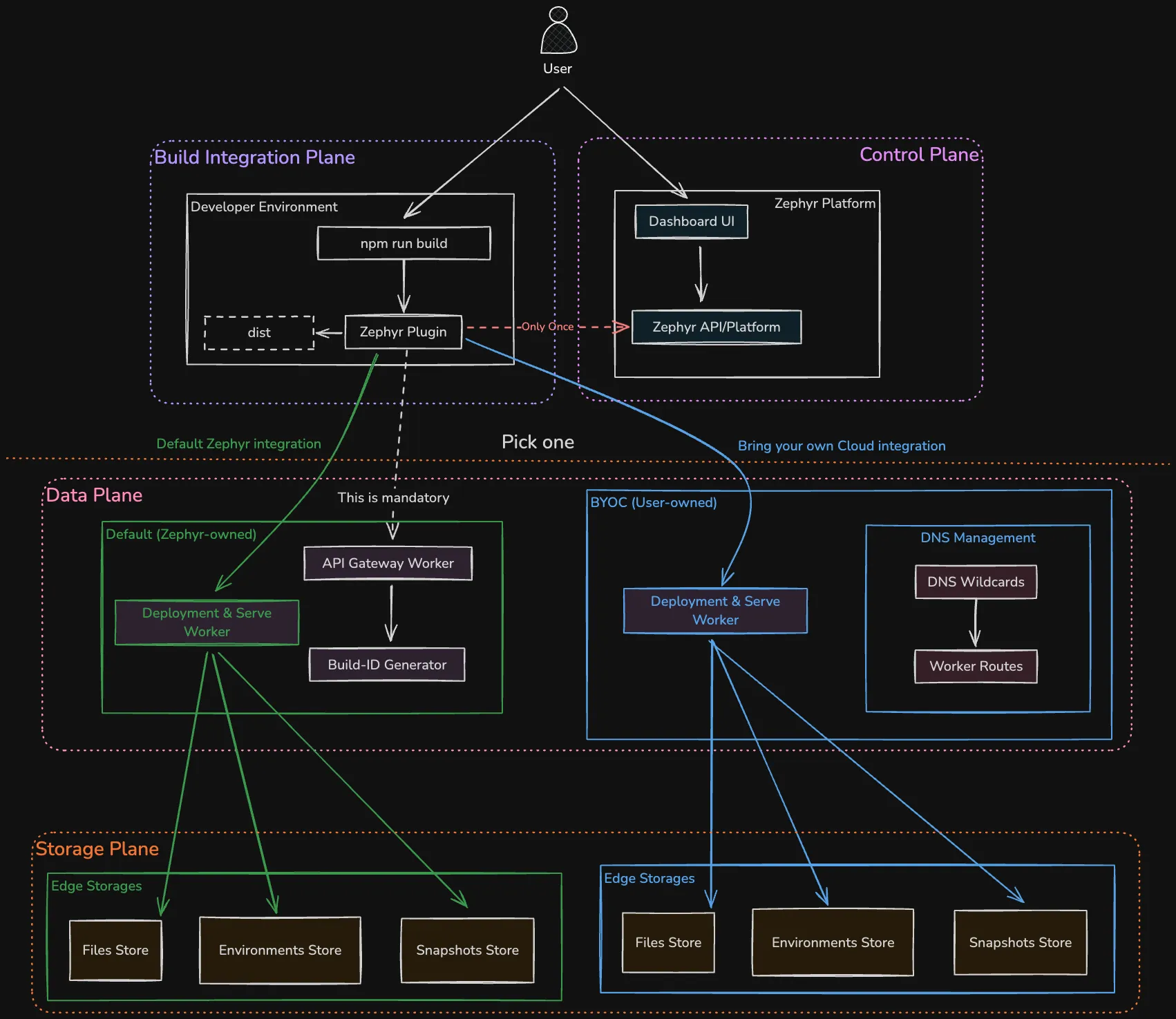
The Zephyr platform consists of four primary subsystems that work together to provide seamless deployment and serving capabilities:
-
Build Integration Plane: The entry point for developers, implemented as plugins for popular bundlers (Webpack, Rspack, Vite, etc...).
These plugins intercept build lifecycle events to analyze outputs, extract metadata, and initiate the deployment process. The integration is designed to be transparent, adding no overhead to the build process and requiring no changes to existing configurations. See the bundler guides and integration guides for implementation details.
-
Control Plane: The centralized management system comprising the Zephyr Cloud's API platform and dashboard UI.
It handles authentication, authorization, project management, and deployment orchestration. The control plane maintains the source of truth for all deployments and provides both programmatic and visual interfaces for management.
-
Data Plane: The distributed edge infrastructure responsible for serving applications.
Implemented as edge workers across multiple cloud providers, it handles request routing, asset serving, and dynamic configuration. The data plane operates independently of the control plane, ensuring high availability even during control plane maintenance.
-
Storage Plane: A distributed storage system built entirely on edge KV stores.
All deployment data is stored in globally distributed KV stores that provide sub-millisecond access times. The storage layer implements content-addressed storage with automatic replication across multiple regions, ensuring fast serving through edge workers regardless of user location.
In BYOC deployments, the KV store implementation varies by cloud provider and its capabilities. See the Cloud Providers guide for details on specific implementations.
Build Integration Architecture
The build integration plane represents the most critical component of Zephyr's architecture, as it must balance several competing requirements: zero performance impact, complete transparency, and comprehensive data extraction.
Plugin Design Philosophy
Zephyr's bundler plugins follow a unified architecture pattern across all supported bundlers.
Each plugin implements the same core functionality while adapting to bundler-specific APIs and lifecycle events.
The plugins operate on a principle of "silent observation" - they attach to existing bundler hooks without modifying the build pipeline or affecting output. This approach ensures that builds with Zephyr produce identical artifacts to builds without it, maintaining compatibility with existing CI/CD systems and development workflows.
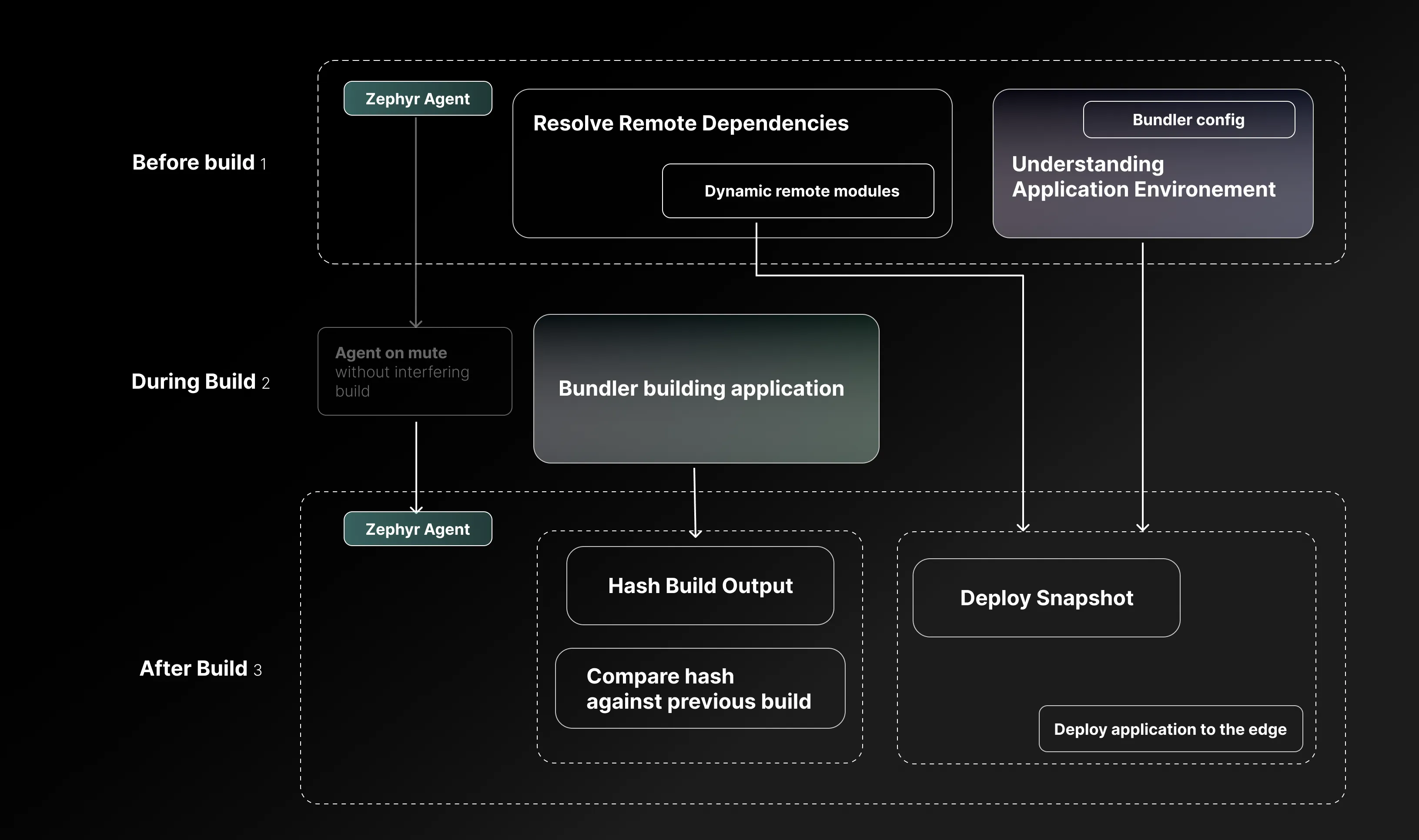
Lifecycle Integration Points
The Zephyr agent activates during the bundler initialization phase and attaches to specific lifecycle hooks that vary by bundler:
-
Initialization Phase: During bundler startup, the agent performs authentication, validates project access, and establishes a connection to the Zephyr API. This phase also involves analyzing the build configuration to understand the application structure, including entry points, output paths, and module federation settings.
-
Build Observation Phase: As the bundler processes modules, the agent monitors the dependency graph construction without interfering with the build process. For module federation applications, it tracks the relationships between host and remote applications, shared dependencies, and exposed modules. This information is crucial for optimizing the serving strategy and enabling dynamic module resolution at runtime.
-
Post-build Analysis Phase: Once the bundler completes, the agent analyzes the build output to extract critical metadata. This includes generating a complete asset manifest with content hashes, identifying code splitting boundaries, and mapping source files to output chunks. For applications using module federation, the agent also generates a runtime configuration that enables dynamic import resolution without hardcoded URLs.
Asset Processing Pipeline
The asset processing pipeline is designed to handle the diverse output formats produced by different bundlers while maintaining consistency in the deployment process.
- Asset Classification: Upon build completion, the agent classifies assets into categories based on their characteristics and intended use. JavaScript bundles are analyzed for module boundaries and dependency relationships. CSS files are parsed to extract critical styles and identify font dependencies. Static assets like images and fonts are cataloged with their content types and compression characteristics.
The asset classification step is going to change in the near future to support a more decoupled approach from the Platform API. This new approach will not require communication between the Edge Worker and the Platform API during authentication.
-
Content Hashing Strategy: Every asset undergoes content-based hashing using SHA-256, creating a unique identifier that enables perfect caching and deduplication. The hashing process is hierarchical - individual files are hashed first, then chunks (groups of related files) receive aggregate hashes, and finally a snapshot hash is computed as the Merkle root of all assets.
-
Differential Upload Optimization: The upload process implements several optimizations to minimize deployment time. Content-based deduplication ensures that unchanged assets are never re-uploaded. Block-level differencing identifies modified sections within large files, uploading only the changed portions.
The asset map serves as the definitive record of a deployment, containing not just file listings but comprehensive metadata about each asset. This includes content hashes for cache validation, compression settings for optimal serving, MIME types for correct content negotiation, and dependency relationships for intelligent prefetching. The asset map is immutable once created, ensuring deployments can be perfectly reproduced.
Zephyr Manifest
During the build process, Zephyr generates a zephyr-manifest.json file that captures configuration elements intended for environment-level runtime overrides. This manifest serves as the foundation for Zephyr's dynamic environment override system.
Manifest Contents:
- Remote Dependencies: All dependencies declared in the
zephyr:dependenciesfield ofpackage.json, including their resolution rules and build-time values - Build-Time Environment Variables: All environment variables prefixed with
ZE_PUBLIC_captured during the build process
The manifest is generated automatically and requires no direct interaction from developers. It's included in the build output and uploaded as part of the deployment process.
Runtime Override System:
The manifest enables Zephyr's environment-level override capabilities:
- Remote Dependency Overrides: At runtime, each deployment environment can override which version, tag, or environment of a remote dependency to load, independent of the build-time declaration
- Environment Variable Overrides: Each environment can inject different values for
ZE_PUBLIC_variables without rebuilding the application
This architecture enables "build once, deploy everywhere" workflows where a single build artifact can be deployed to multiple environments with environment-specific configuration. The manifest provides the baseline configuration while the environment settings provide the runtime overrides.
For detailed information on using environment-level overrides, see Environment-Level Overrides.
Deployment Architecture
The deployment system is designed for reliability, speed, and flexibility, supporting both Zephyr-managed infrastructure and customer-controlled environments.
Infrastructure Models
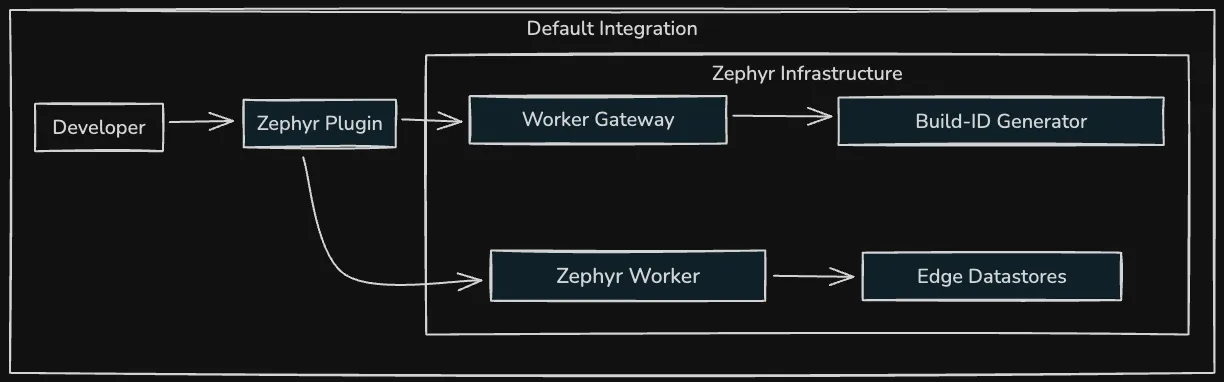
-
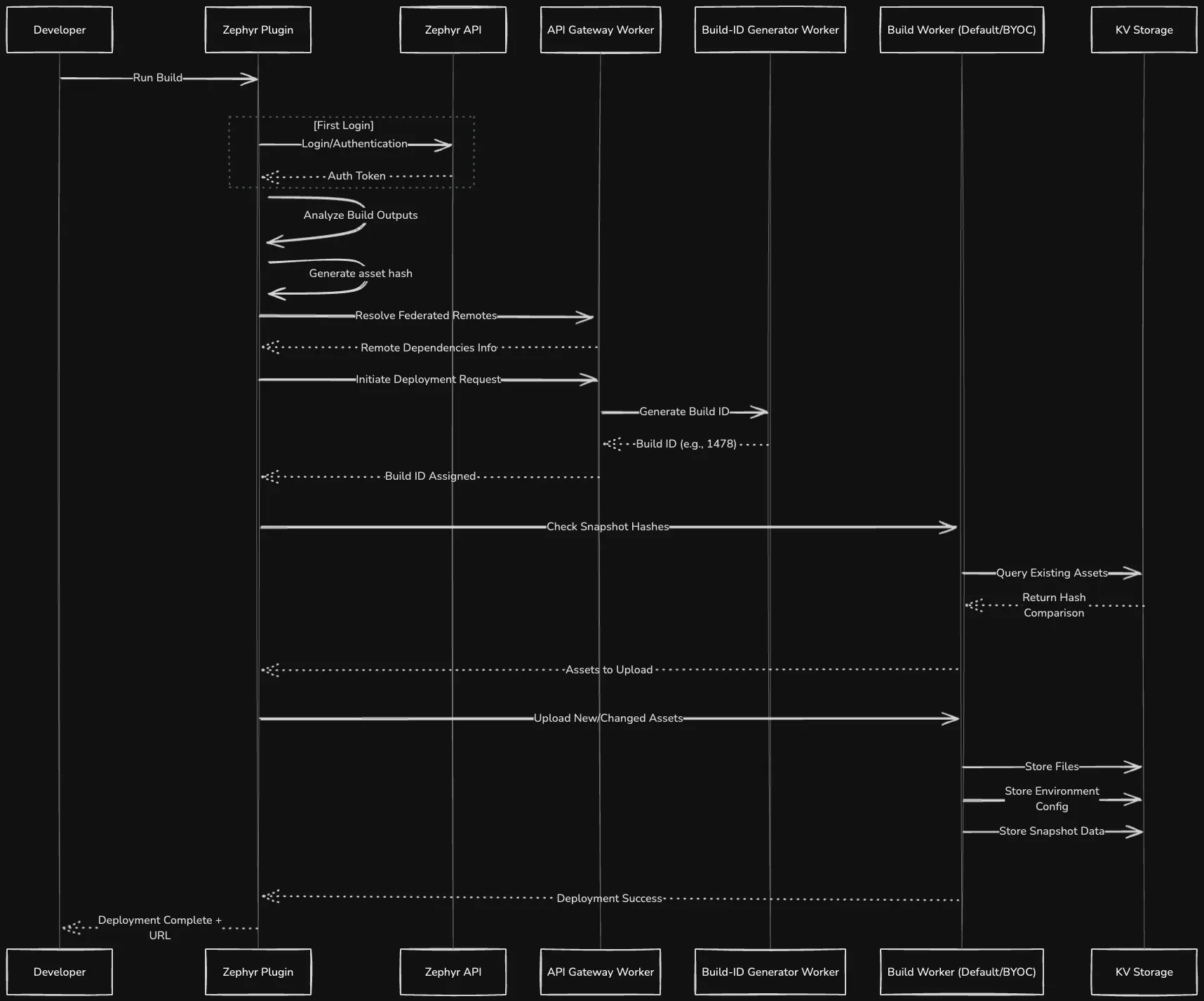
Managed Infrastructure Model: In the default configuration, Zephyr provides a fully managed deployment pipeline.
The API Gateway Worker handles incoming deployments, performing authentication and routing to appropriate processing workers.
The Build-ID Generator creates globally unique identifiers that enable consistent versioning across distributed systems.
The Deployment Worker orchestrates the distribution of assets to edge locations, managing replication and confirming successful deployment.
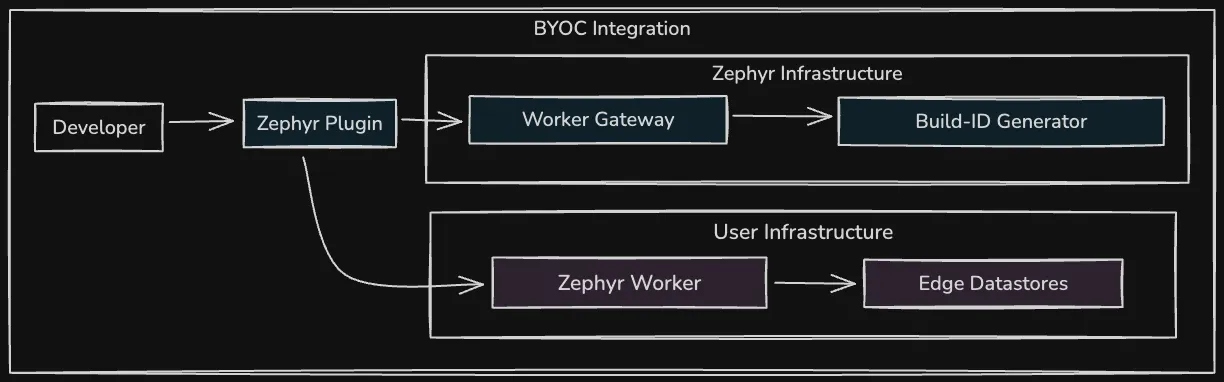
-
BYOC (Bring Your Own Cloud) Model: For organizations with specific compliance or control requirements, Zephyr supports deployment to customer-owned infrastructure.
In this model, the control plane remains managed by Zephyr, providing orchestration and configuration management, while the data plane (workers and storage) runs in the customer's cloud accounts.
This hybrid approach maintains the ease of use of the managed service while providing complete data sovereignty.
Deployment Process
The deployment process is designed for atomicity and reliability. When a deployment is initiated, the system first validates that all required assets are available and correctly hashed. It then creates an immutable snapshot record that captures the complete state of the deployment. The snapshot is replicated to multiple regions before any traffic routing changes occur.
Once the snapshot is confirmed available in all required regions, the system updates the environment configuration in a single atomic operation. This approach ensures that users always see a consistent version of the application, with no possibility of mixed asset versions. The previous version remains available for instant rollback if needed.
Application UID

Every application in Zephyr is identified by a unique Application UID that follows a deterministic structure:
This UID is automatically derived from:
- application: The
namefield in yourpackage.json. - project: The repository name from your git context.
- organization: The GitHub/GitLab organization name.
If the VCS is within a custom organization or enterprise account, the organization name is derived from the custom domain name.
For example, an application with:
package.jsonname:"shell-vibe"- Repository:
swalker326 - Organization:
zephyr-cloud
Would have the Application UID: shell-vibe.swalker326.zephyr-cloud
This UID serves as the primary key throughout Zephyr's infrastructure and enables:
- Consistent identification across all deployment environments
- Direct mapping to storage keys in the KV stores
- Permission boundaries for access control
- Automatic URL generation for deployments
Default Privacy Settings
Organizations, projects, and applications in Zephyr are private by default in the dashboard. This means:
- Private organizations can only be navigated to in the dashboard by their members
- Private projects are only visible to members of the organization
- Private applications only appear in the dashboards of authorized organization members
- If set to public, anyone with the dashboard URL can navigate to and view these resources
Note: This privacy setting only affects dashboard visibility. Deployed application URLs remain publicly accessible regardless of these settings.
Serving Architecture
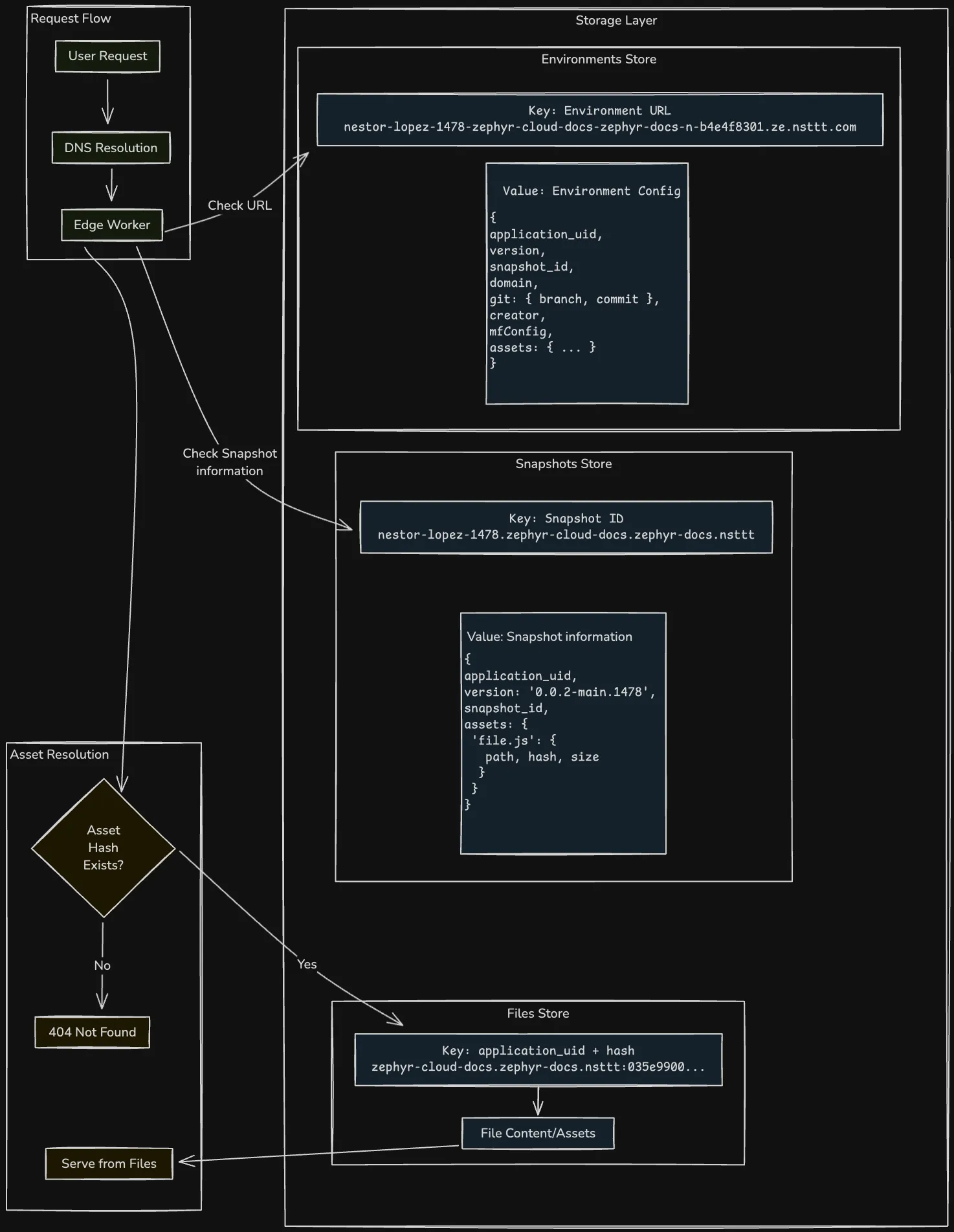
The serving plane is optimized for minimal latency and maximum availability, leveraging a globally distributed edge network to serve applications as close to users as possible.
Request Processing Pipeline
When a user request arrives at an edge location, it undergoes a multi-stage processing pipeline designed for efficiency and correctness. The initial DNS resolution uses GeoDNS to route requests to the nearest healthy edge location, with automatic failover to secondary locations if the primary is unavailable.
DNS setup varies based on deployment model and provider.
Upon reaching the edge worker, the request is parsed to extract the hostname and path. The worker then performs a series of lookups against the storage plane, with each storage type optimized for specific access patterns. The Environment Store, implemented as a distributed KV store, provides millisecond lookup of the current deployment configuration for a given hostname. This configuration includes the active snapshot ID, versioning information etc...
Storage Architecture
The storage plane implements a three-tier architecture, each tier optimized for different access patterns and data characteristics:
-
Environment Store: A globally replicated KV store containing hostname-to-configuration mappings. Each entry is approximately 1KB and includes the active snapshot ID, custom headers, redirect rules, and feature flags. The store implements strong consistency for writes with eventual consistency for reads, ensuring configuration changes propagate globally within seconds.
-
Snapshots Store: An immutable store containing deployment manifests. Each snapshot includes a complete asset manifest with paths, content hashes, and metadata. Snapshots are typically 10-100KB and are cached aggressively at edge locations. The immutable nature of snapshots enables perfect caching with no invalidation complexity.
-
Files Store: A content-addressed object store containing the actual file contents. Files are stored with their content hash as the key, enabling perfect deduplication across deployments.
Each provider offers different performance characteristics, pricing models, and regional availability. Learn more in the Cloud Providers documentation.
Related Documentation
Core Features:
- Versions - Version management and immutability
- Remote Dependencies - Dependency resolution system
- Environment Overrides - Runtime configuration system
- Tags & Environments - Deployment management
Implementation:
- Quick Start - Get started with Zephyr
- Bundler Guides - Integration with different build tools
- Cloud Providers - BYOC deployment options
- Module Federation Guide - Micro-frontends architecture